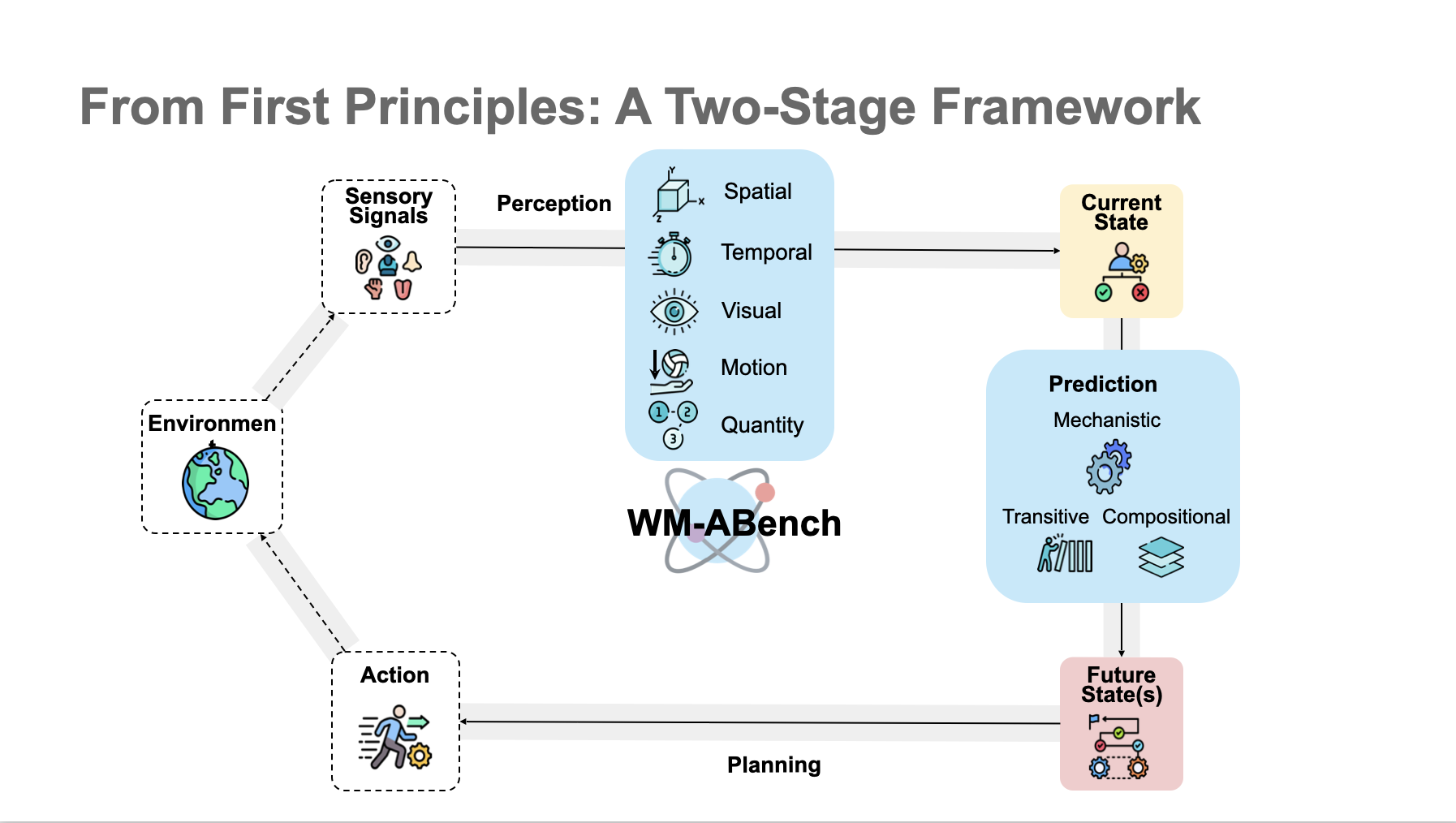
Internal world models (WMs) enable agents to understand the world's state and predict transitions, serving as the basis for advanced deliberative reasoning. Recent large Vision-Language Models (VLMs), such as OpenAI o3, GPT-4o and Gemini, exhibit potential as general-purpose WMs. While the latest studies have evaluated and shown limitations in specific capabilities such as visual understanding, a systematic evaluation of VLMs' fundamental WM abilities remains absent. Drawing on comparative psychology and cognitive science, we propose a two-stage framework that assesses perception (visual, spatial, temporal, quantitative, and motion) and prediction (mechanistic simulation, transitive inference, compositional inference) to provide an atomic evaluation of VLMs as WMs. Guided by this framework, we introduce WM-ABench, a large-scale benchmark comprising 23 fine-grained evaluation dimensions across 6 diverse simulated environments with controlled counterfactual simulations. Through 660 experiments on 15 latest commercial and open-source VLMs, we find that these models exhibit striking limitations in basic world modeling abilities. For instance, almost all models perform at near-random accuracy when distinguishing motion trajectories. Additionally, they lack disentangled understanding---e.g., some models tend to believe blue objects move faster than green ones. More rich results and analyses reveal significant gaps between VLMs and human-level world modeling.


| Spatial Perception | ||||||
|---|---|---|---|---|---|---|
| # | Model | Average | Spatial Relation | Spatial Vacancy | Spatial Occupancy | Spatial Positioning |
| 1 | NVILA | 57.94 | 47.50 | 64.69 | 88.90 | 31.13 |
| 2 | QWen2-VL-72b | 62.72 | 57.42 | 49.80 | 90.61 | 53.05 | 3 | QWen2.5-VL-72b | 63.52 | 64.19 | 53.61 | 95.50 | 40.80 |
| 4 | InternVL2.5-78b | 61.05 | 54.98 | 62.39 | 95.72 | 31.10 |
| 5 | Llama 3.2 vision-90b | 43.18 | 49.09 | 46.92 | 51.88 | 24.83 |
| 6 | LLaVA-OneVision | 59.68 | 66.40 | 54.85 | 93.71 | 23.75 |
| 7 | Claude 3.5 Sonnet | 57.01 | 54.77 | 61.09 | 72.89 | 36.80 |
| 8 | Gemini-1.5-flash | 53.69 | 56.79 | 50.02 | 80.10 | 27.88 |
| 9 | Gemini-1.5-pro | 66.47 | 67.34 | 66.23 | 88.24 | 44.08 |
| 10 | GPT-4o | 65.10 | 56.91 | 68.22 | 87.73 | 47.55 |
| 11 | GPT-4o-mini | 51.93 | 37.67 | 65.19 | 66.74 | 38.15 | 12 | o3* | 54.65 | 88.00 | 93.50 | 98.50 | 59.00 |
| 13 | Gemini-2.5-pro* | 84.75 | 88.00 | 93.50 | 98.50 | 59.00 |
| 14 | Claude 3.7 Sonnet* | 67.38 | 64.00 | 68.00 | 72.50 | 65.00 |
| 15 | GPT-4.5-preview* | 67.50 | 75.50 | 53.50 | 93.50 | 47.50 |
| * | Random | 37.50 | 25.00 | 50.00 | 50.00 | 25.00 |
| * | Human | 94.75 | 95.00 | 99.00 | 93.00 | 92.00 |
| Temporal Perception | ||||
|---|---|---|---|---|
| # | Model | Average | Temporal Positioning | Temporal Extension |
| 1 | NVILA | 34.08 | 47.30 | 20.85 |
| 2 | QWen2-VL-72b | 52.95 | 60.99 | 44.91 | 3 | QWen2.5-VL-72b | 47.43 | 50.63 | 44.23 |
| 4 | InternVL2.5-78b | 52.66 | 53.55 | 51.78 |
| 5 | Llama 3.2 vision-90b | 31.34 | 25.10 | 37.59 |
| 6 | LLaVA-OneVision | 31.91 | 34.79 | 29.03 |
| 7 | Claude 3.5 Sonnet | 41.76 | 45.55 | 37.97 |
| 8 | Gemini-1.5-flash | 44.49 | 44.22 | 44.77 |
| 9 | Gemini-1.5-pro | 55.52 | 51.46 | 59.59 |
| 10 | GPT-4o | 35.81 | 41.62 | 30.01 |
| 11 | GPT-4o-mini | 37.10 | 39.40 | 34.80 |
| 12 | o3* | 61.25 | 66.00 | 56.50 |
| 13 | Gemini-2.5-pro* | 47.75 | 59.50 | 36.00 |
| 14 | Claude 3.7 Sonnet* | 36.10 | 36.69 | 35.50 |
| 15 | GPT-4.5-preview* | 58.75 | 56.50 | 61.00 |
| * | Random | 33.33 | 33.33 | 33.33 |
| * | Human | 84.5 | 81.00 | 88.00 |
| Vision Perception | |||||
|---|---|---|---|---|---|
| # | Model | Average | Color | Shape | Material |
| 1 | NVILA | 84.29 | 91.30 | 98.25 | 56.30 |
| 2 | QWen2-VL-72b | 87.12 | 92.91 | 98.91 | 63.70 |
| 3 | QWen2.5-VL-72b | 81.77 | 92.04 | 91.53 | 51.45 |
| 4 | InternVL2.5-78b | 83.58 | 92.34 | 95.70 | 53.94 |
| 5 | Llama 3.2 vision-90b | 82.95 | 91.11 | 95.58 | 50.00 |
| 6 | LLaVA-OneVision | 88.39 | 91.96 | 98.42 | 71.24 |
| 7 | Claude 3.5 Sonnet | 62.69 | 52.28 | 96.20 | 50.00 |
| 8 | Gemini-1.5-flash | 83.76 | 93.16 | 98.70 | 50.00 |
| 9 | Gemini-1.5-pro | 81.28 | 92.97 | 89.20 | 50.00 |
| 10 | GPT-4o | 85.21 | 93.30 | 98.70 | 55.60 |
| 11 | GPT-4o-mini | 83.91 | 92.97 | 99.70 | 50.00 |
| 12 | o3* | 84.75 | 93.50 | 99.0 | 54.0 |
| 13 | Gemini-2.5-pro* | 84.25 | 93.50 | 99.0 | 55.0 |
| 14 | Claude 3.7 Sonnet* | 85.25 | 51.64 | 98.00 | 53.00 |
| 15 | GPT-4.5-preview* | 63.57 | 95.00 | 98.00 | 51.00 |
| * | Random | 33.33 | 25.00 | 25.00 | 50.00 |
| * | Human | 92.67 | 94.00 | 100.00 | 84.00 |
| Motion Perception | ||||||
|---|---|---|---|---|---|---|
| # | Model | Average | Motion Speed | Motion Direction | Motion Identification | Motion Trajectory |
| 1 | NVILA | 38.71 | 47.90 | 53.05 | 34.30 | 19.60 |
| 2 | QWen2-VL-72b | 58.67 | 46.03 | 85.41 | 77.73 | 25.50 | 3 | QWen2.5-VL-72b | 55.90 | 65.18 | 70.87 | 63.25 | 28.29 |
| 4 | InternVL2.5-78b | 55.90 | 39.39 | 90.30 | 78.87 | 28.49 |
| 5 | Llama 3.2 vision-90b | 31.83 | 34.92 | 43.76 | 23.77 | 24.87 |
| 6 | LLaVA-OneVision | 36.59 | 42.86 | 53.62 | 29.59 | 20.28 |
| 7 | Claude 3.5 Sonnet | 50.95 | 52.52 | 69.77 | 48.25 | 33.27 |
| 8 | Gemini-1.5-flash | 37.93 | 39.74 | 62.80 | 32.60 | 18.04 |
| 9 | Gemini-1.5-pro | 42.53 | 47.43 | 61.05 | 32.60 | 29.04 |
| 10 | GPT-4o | 38.86 | 34.75 | 54.51 | 36.80 | 29.40 |
| 11 | GPT-4o-mini | 36.02 | 30.41 | 35.15 | 52.68 | 21.87 |
| 12 | o3* | 70.63 | 45.00 | 92.50 | 86.00 | 59.00 |
| 12 | Gemini-2.5-pro* | 56.50 | 55.00 | 74.50 | 53.00 | 43.50 |
| 12 | Claude 3.7 Sonnet* | 43.69 | 46.50 | 64.80 | 40.00 | 23.50 |
| 12 | GPT-4.5-preview* | 63.13 | 41.00 | 83.50 | 40.00 | 44.50 |
| * | Random | 27.08 | 33.33 | 25.00 | 25.00 | 25.00 |
| * | Human | 92.75 | 87.00 | 99.00 | 97.00 | 88.00 |
| Quantity Perception | |||||
|---|---|---|---|---|---|
| # | Model | Average | Discrete Quantity | Continuous Quantity | Relative Quantity |
| 1 | NVILA | 66.93 | 69.61 | 63.89 | 65.78 |
| 2 | QWen2-VL-72b | 76.79 | 79.37 | 75.53 | 74.84 | 3 | QWen2.5-VL-72b | 78.57 | 78.88 | 87.96 | 73.56 |
| 4 | InternVL2.5-78b | 75.16 | 78.90 | 76.70 | 70.65 |
| 5 | Llama 3.2 vision-90b | 69.46 | 68.66 | 72.00 | 69.00 |
| 6 | LLaVA-OneVision | 75.25 | 72.18 | 81.08 | 75.40 |
| 7 | Claude 3.5 Sonnet | 61.85 | 75.10 | 43.37 | 57.84 |
| 8 | Gemini-1.5-flash | 74.77 | 78.95 | 80.56 | 67.70 |
| 9 | Gemini-1.5-pro | 77.97 | 84.00 | 79.76 | 71.04 |
| 10 | GPT-4o | 65.59 | 59.13 | 87.30 | 61.21 |
| 11 | GPT-4o-mini | 56.00 | 45.74 | 73.94 | 57.29 |
| 12 | o3* | 91.20 | 87.50 | 96.00 | 92.50 |
| 13 | Gemini-2.5-pro* | 89.40 | 86.50 | 89.00 | 92.50 |
| 14 | Claude 3.7 Sonnet* | 61.60 | 70.50 | 49.00 | 59.00 |
| 15 | GPT-4.5-preview* | 76.60 | 74.00 | 89.00 | 73.00 |
| * | Random | 36.10 | 25.00 | 50.00 | 33.30 |
| * | Human | 98.67 | 99.00 | 98.00 | 99.00 |
| Mechanistic Simulation | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| # | Model | Average | Outdoor Navigation | Indoor Navigation | Collide | Slide | Drop | Robot Arm Drop | Robot Arm Lift | Robot Arm Push |
| 1 | NVILA | 34.3 | 31.3 | 16.7 | 28.4 | 44.6 | 44.7 | 48.9 | 33.8 | 26.4 |
| 2 | QWen2-VL-72b | 58.1 | 62.0 | 65.3 | 30.4 | 40.3 | 59.2 | 95.3 | 91.9 | 20.0 | 3 | QWen2.5-VL-72b | 62.3 | 76.6 | 70.9 | 36.5 | 51.9 | 55.0 | 89.8 | 85.5 | 31.9 |
| 4 | InternVL2.5-78b | 49.0 | 57.9 | 54.6 | 24.9 | 41.3 | 51.3 | 73.7 | 60.3 | 28.1 |
| 5 | Llama 3.2 vision-90b | 25.7 | 24.7 | 33.3 | 24.0 | 25.4 | 24.7 | 23.7 | 26.3 | 23.1 |
| 6 | LLaVA-OneVision | 28.1 | 19.0 | 57.9 | 25.8 | 20.5 | 19.4 | 26.1 | 30.8 | 25.1 |
| 7 | Claude 3.5 Sonnet | 40.2 | 36.3 | 39.6 | 15.0 | 22.1 | 36.7 | 86.3 | 57.7 | 28.0 |
| 8 | Gemini-1.5-flash | 42.2 | 36.8 | 41.1 | 27.3 | 30.2 | 42.2 | 75.7 | 65.8 | 18.4 |
| 9 | Gemini-1.5-pro | 54.6 | 44.3 | 57.6 | 47.5 | 37.6 | 60.1 | 79.4 | 76.8 | 33.5 |
| 10 | GPT-4o | 55.4 | 61.6 | 69.6 | 39.2 | 37.6 | 49.4 | 83.9 | 71.2 | 30.3 |
| 11 | GPT-4o-mini | 45.6 | 45.8 | 34.0 | 25.8 | 32.9 | 49.9 | 77.7 | 68.2 | 30.9 |
| 12 | o3* | 75.3 | 85.00 | 87.00 | 60.00 | 78.00 | 79.00 | 80.00 | 83.00 | 50.00 |
| 13 | Gemini-2.5-pro* | 69.9 | 81.00 | 77.00 | 53.00 | 68.00 | 73.00 | 87.00 | 76.00 | 44.00 |
| 14 | Claude 3.7 Sonnet* | 57.12 | 59.00 | 51.00 | 38.54 | 48.98 | 67.67 | 96.00 | 56.38 | 39.36 |
| 15 | GPT-4.5-preview* | 59.13 | 71.00 | 34.00 | 55.00 | 72.00 | 56.00 | 86.00 | 59.00 | 40.00 |
| * | Random | 25.00 | 25.00 | 25.00 | 25.00 | 25.00 | 25.00 | 25.00 | 25.00 | 25.00 |
| * | Human | 97.50 | 98.00 | 98.00 | 100.00 | 98.00 | 86.00 | 100.00 | 100.00 | 100.00 |
| Transitivity | ||||||||
|---|---|---|---|---|---|---|---|---|
| # | Model | Average | Outdoor Navigation | Indoor Navigation | Robot Arm Push-Pick | Robot Arm Pick-Rotate | ||
| 1 | NVILA | 23.03 | 32.43 | 4.24 | 29.05 | 26.39 | ||
| 2 | QWen2-VL-72b | 45.21 | 50.14 | 43.80 | 55.7 | 31.21 | 3 | QWen2.5-VL-72b | 37.77 | 61.08 | 34.71 | 24.40 | 30.90 |
| 4 | InternVL2.5-78b | 38.34 | 51.07 | 31.90 | 36.65 | 34.72 | ||
| 5 | Llama 3.2 vision-90b | 25.98 | 23.90 | 33.59 | 25.61 | 20.80 | ||
| 6 | LLaVA-OneVision | 24.27 | 22.57 | 26.70 | 25.41 | 22.39 | ||
| 7 | Claude 3.5 Sonnet | 34.15 | 35.29 | 27.51 | 36.28 | 37.50 | ||
| 8 | Gemini-1.5-flash | 39.83 | 40.71 | 38.96 | 42.65 | 36.98 | ||
| 9 | Gemini-1.5-pro | 43.40 | 48.14 | 43.32 | 46.20 | 35.94 | ||
| 10 | GPT-4o | 43.44 | 42.64 | 43.20 | 42.42 | 45.49 | ||
| 11 | GPT-4o-mini | 34.61 | 41.64 | 24.44 | 32.93 | 39.41 | ||
| 12 | o3* | 50.50 | 61.00 | 51.00 | 42.00 | 48.00 | ||
| 13 | Gemini-2.5-pro* | 57.25 | 66.00 | 67.00 | 42.00 | 54.00 | ||
| 14 | Claude 3.7 Sonnet* | 38.18 | 44.00 | 26.00 | 34.34 | 48.39 | ||
| 14 | GPT-4.5-preview* | 40.00 | 47.00 | 34.00 | 44.00 | 35.00 | ||
| * | Random | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | ||
| * | Human | 82.50 | 78.0 | 90.0 | 80.0 | 82.0 | ||
| Compositionality | |||||||
|---|---|---|---|---|---|---|---|
| # | Model | Average | Collide | Robot Arm Push | Robot Arm Lift | ||
| 1 | NVILA | 27.96 | 26.62 | 25.48 | 31.77 | ||
| 2 | QWen2-VL-72b | 39.14 | 24.31 | 51.30 | 41.80 | 3 | QWen2.5-VL-72b | 30.54 | 21.62 | 34.80 | 35.20 |
| 4 | InternVL2.5-78b | 38.29 | 40.12 | 46.96 | 27.78 | ||
| 5 | Llama 3.2 vision-90b | 25.09 | 25.85 | 24.13 | 25.30 | ||
| 6 | LLaVA-OneVision | 25.20 | 22.38 | 25.00 | 28.23 | ||
| 7 | Claude 3.5 Sonnet | 43.96 | 38.97 | 41.90 | 51.00 | ||
| 8 | Gemini-1.5-flash | 39.07 | 40.20 | 30.80 | 46.18 | ||
| 9 | Gemini-1.5-pro | 40.16 | 34.10 | 36.80 | 49.57 | ||
| 10 | GPT-4o | 30.74 | 22.78 | 33.81 | 35.63 | ||
| 11 | GPT-4o-mini | 36.25 | 37.23 | 40.76 | 30.77 | ||
| 12 | o3* | 35.67 | 33.00 | 37.00 | 37.00 | ||
| 13 | Gemini-2.5-pro* | 47.33 | 38.00 | 47.00 | 57.00 | ||
| 14 | Claude 3.7 Sonnet* | 39.99 | 41.49 | 29.03 | 49.46 | ||
| 15 | GPT-4.5-preview* | 37.33 | 32.00 | 41.00 | 39.00 | ||
| * | Random | 25.0 | 25.0 | 25.0 | 25.0 | ||
| * | Human | 90.67 | 84.0 | 88.0 | 100.0 | ||
* Frontier VLMs evaluated on subset of WM-ABench.
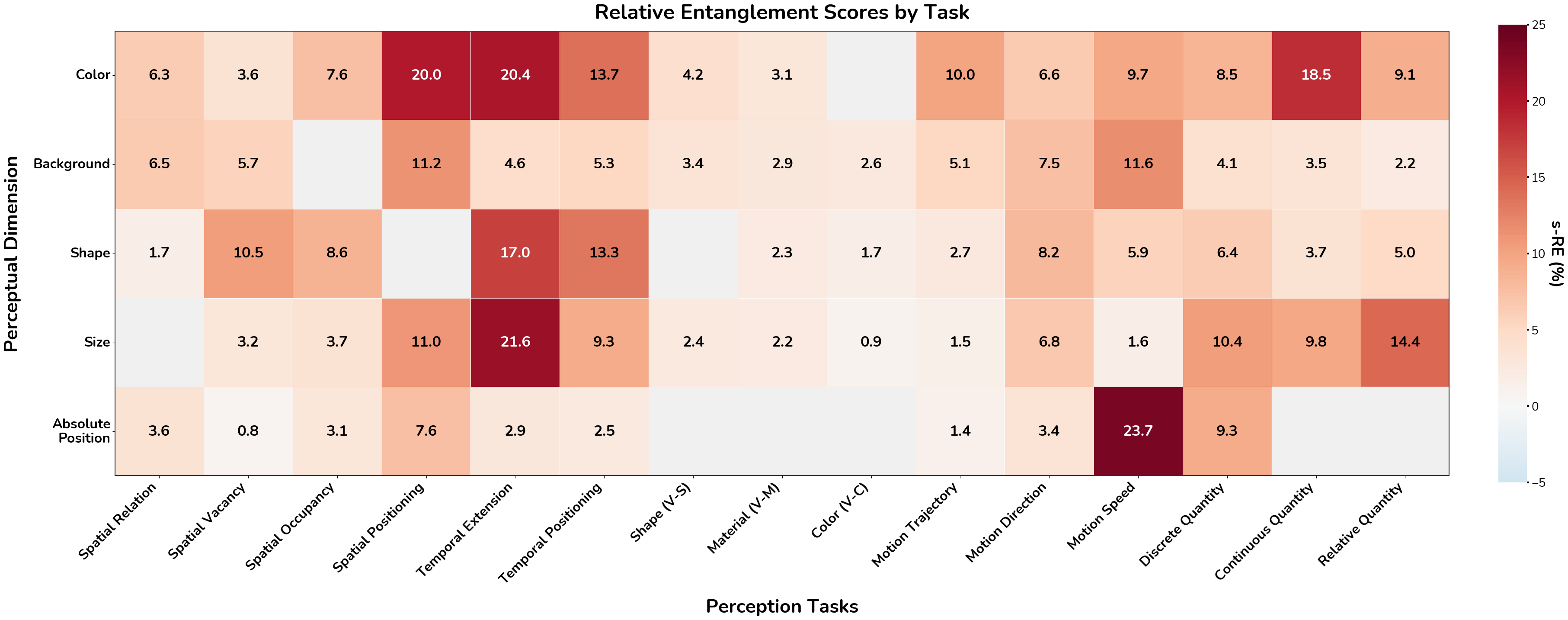
Finding 1: VLMs tend to entangle irrelevant physical concepts (Figure 1).
When we change one dimension, like color, while keeping others constant, we find that models' perception across almost all dimensions will be affected, such as the object's size and speed. Systematic evaluation shows that color and shape emerge as the most influential attributes across the tasks.
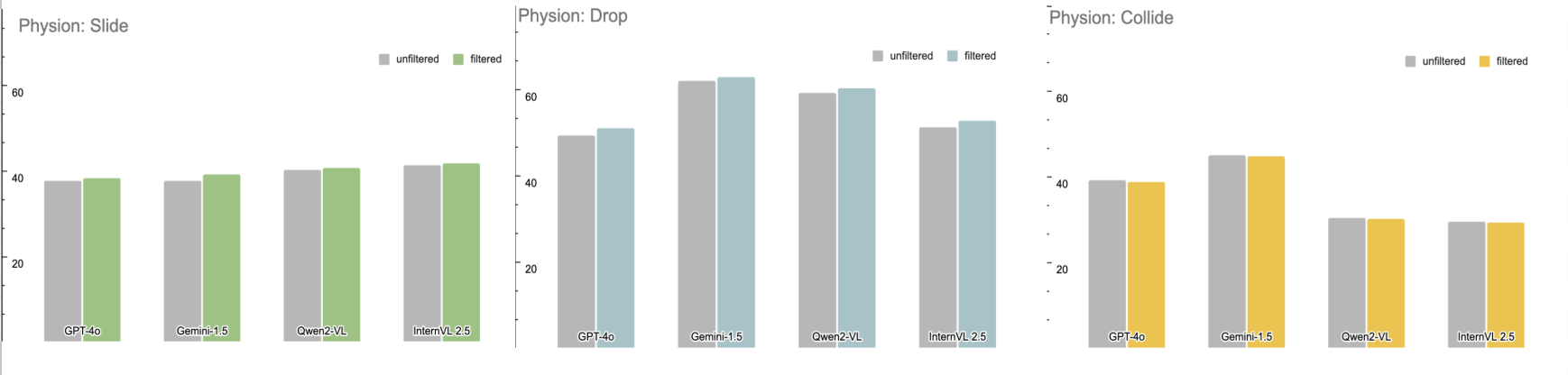
Finding 2: Accurate perception does not guarantee accurate prediction (Figure 2).
Even when models perfectly perceive the current state, they still fail at predicting physical outcomes on three tasks. This suggests that perception errors aren't the sole cause of poor prediction. Models lack the fundamental physical knowledge necessary to simulate object interactions accurately.
@misc{gao2025visionlanguagemodelsinternalworld,
title={Do Vision-Language Models Have Internal World Models? Towards an Atomic Evaluation},
author={Qiyue Gao and Xinyu Pi and Kevin Liu and Junrong Chen and Ruolan Yang and Xinqi Huang and Xinyu Fang and Lu Sun and Gautham Kishore and Bo Ai and Stone Tao and Mengyang Liu and Jiaxi Yang and Chao-Jung Lai and Chuanyang Jin and Jiannan Xiang and Benhao Huang and Zeming Chen and David Danks and Hao Su and Tianmin Shu and Ziqiao Ma and Lianhui Qin and Zhiting Hu},
year={2025},
eprint={2506.21876},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2506.21876}
}